Security NEWS TOPに戻る
バックナンバー TOPに戻る

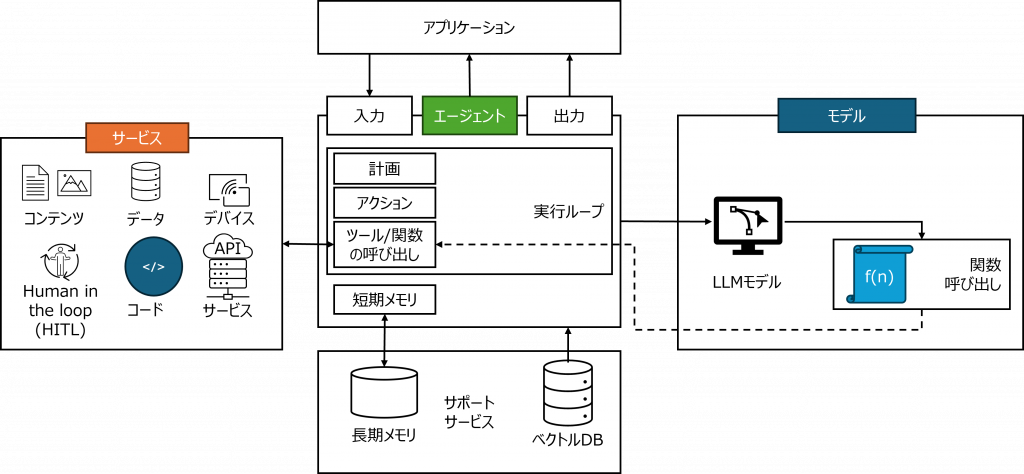
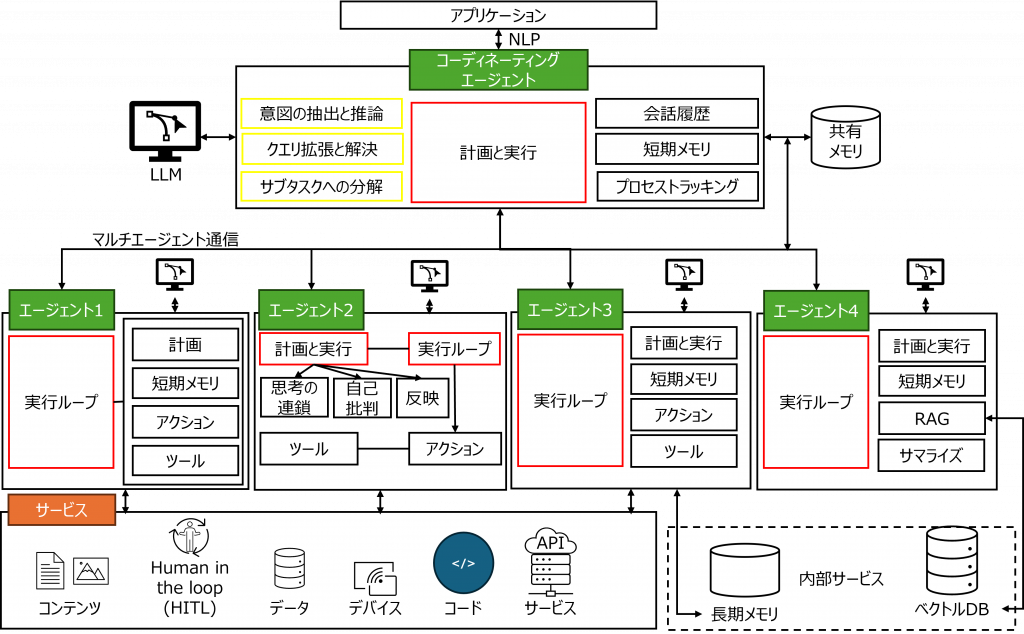
前回記事で述べたように、AIエージェントの普及に伴い、MCP(Model Context Protocol)やA2A(Agent-to-Agent Protocol)の実装事例が増えています。しかし、標準化が進む一方で、脆弱性やセキュリティリスクも現実化しつつあります。本記事では、AIエージェントの基盤を支える標準プロトコル「MCP(Model Context Protocol)」と「A2A(Agent-to-Agent Protocol)」をさらに深く掘り下げ、AIエージェントを安全に活用するための設計指針と実装上の留意点を整理します。
※本稿は2025年7月上旬に執筆しているものです。ご覧いただく時期によっては古い情報となっている場合もありますので、ご承知おきください。
MCPの脆弱性
MCPの脆弱性の事例としては以下のものが挙げられます。
AsanaのMCPサーバの事例
プロジェクトやタスクを一元管理するプラットフォーム(SaaS)・Asanaが2025年5月から提供し始めたMCPサーバに脆弱性があったもの。脆弱性により、MCPを使用しているユーザーが、LLMと接続しているチャットインターフェース越しに他の組織のプロジェクト、チーム、タスクを含むAsanaオブジェクトを取得できた可能性があるとされています*1。前回ご紹介した「図4:MCP関連の主なセキュリティ課題」にも挙げたように、最小特権の付与の原則の徹底(SaaS提供事業者の場合にはテナント間の厳密な分離も含みます)、リクエストやLLMの生成クエリのログの記録といった課題が改めて浮き彫りになったといえます。
A2Aのセキュリティ課題
MAESTRO脅威モデリングに当てはめたときには以下のような問題があると指摘されています。なおMAESTRO脅威モデリングについては下表でご紹介します。
表:A2Aプロトコルのセキュリティ課題のMAESTROモデル分析
| レイヤ | 脅威 | 概要 | 被害を受ける人・組織 | 発生確率 | 影響 | 軽減策 |
|---|---|---|---|---|---|---|
| 1 | メッセージ生成攻撃 (回避) | 攻撃者が悪意のある入力を生成し、エージェントのモデルに誤った、偏った、または有害なメッセージを生成させ、通信中の安全メカニズムを迂回する。モデル出力の非決定論的性質が、これらの攻撃の検出と防止をより困難にする。 | A2A エージェントを利用する組織、システムの利用者 | 高 | 大 | 入力検証: エージェントのモデルにコンテンツを送信する前に厳格な入力検証を実施する。入力をサニタイズする。 出力検証: 生成されたメッセージのコンテンツに有害なコンテンツ、矛盾、または予期しない動作がないか確認する。コンテンツフィルタリングを使用する。非決定論的なモデルの動作に対する出力検証の堅牢性を高めるために、アンサンブル法や敵対的訓練などの技術を採用する。 慎重なプロンプト設計: 敵対的攻撃の影響を受けにくいプロンプトを設計する。モデルをガイドするために少数ショットの例を使用する。 |
| モデル抽出 | A2A を介した過度または巧妙な対話により、プロプライエタリモデルの動作やパラメータに関する十分な詳細が提供され、モデルの推論または盗難が可能になる。エージェントの自律性が、予期しない情報漏洩につながる可能性のある、緩やかに制御された対話パターンを促進することで、この問題を増幅させる可能性がある。 | モデル所有者、企業 | 低 | 大(潜在的に) | 厳格なレート制限: セッション/ユーザー/エージェントごとの A2A 対話にレート制限を適用する。 異常検出: プロービングやデータ抽出の試みを示唆する異常なクエリパターンを監視する。 | |
| 2 | データ汚染 (メッセージ部分) | 攻撃者がエージェント間で交換されるメッセージに悪意のあるコンテンツを注入し、意思決定に使用されるデータを侵害する。エージェントの相互作用の動的な性質は、このデータポイズニングが急速に広がり、連鎖的な影響を及ぼす可能性があることを意味する。 | エージェント、A2A エージェントの決定に依存する組織 | 中~高 | 大 | 強力な検証: ファイルの整合性チェック、DataParts のスキーマ検証、TextParts のコンテンツフィルタリングを含む、すべてのメッセージパーツに対する厳格な検証を実施する。 最小特権: 最小特権の原則に基づいて、機密データへのエージェントのアクセスを制限する。 出どころの追跡: メッセージ内のデータの出どころと系統を追跡し、信頼性を評価する。送信元エージェントのIDとデータに適用された変換を考慮するために出どころの追跡を拡張する。 |
| 機微情報の漏洩 | エージェントが、過度に広範な権限、データ管理ミス、またはモデルの幻覚により、A2A 通信または成果物で意図せず機密情報(PII、機密情報)を公開する。 | 個人(PII の所有者)、機密情報を扱う組織 | 中 | 中~大 | 自動 PII 編集: 個人識別情報(PII)の検出と編集のための自動プロセスを採用する(例: Gemini のフィルター機能)。 きめ細かなアクセス制御: エージェントの役割とタスクのコンテキストに応じて堅牢なアクセス制御を実装する。 コンテキスト認識型ガードレール: エージェントが機密情報や制限された情報を共有するのを防ぐためにガードレールを追加する。 | |
| 3 | 許可されていないエージェントのなりすまし | 攻撃者が正当なエージェントになりすまし、機密情報にアクセスしたり、他のエージェントを操作したりする。変化する資格情報や検証可能なクレデンシャルによって示されるエージェント ID の動的な性質は、この脅威をさらに複雑にする。 | 他のエージェント、A2A プロトコルを利用する組織 | 中 | 大 | 分散型識別子(DIDs): エージェントに ID 検証のために DID を使用することを義務付ける。ID の変更を検出するために、DID ドキュメントを定期的に更新および再検証するメカニズムを実装する。 安全な認証: DID ベースの署名や相互 TLS などの強力な認証メカニズムを実装し、エージェントの ID を検証する。リプレイ攻撃を防ぎ、通信時に資格情報が有効であることを確認するために、タイムスタンプ付き署名を使用する。 エージェントレジストリ: エージェントの正当性を検証するために、信頼されたエージェントレジストリを実装する。レジストリは動的なエージェント属性を処理できる必要があり、継続的に更新されるべきである。 |
| メッセージインジェクション攻撃 | 攻撃者が A2A メッセージに悪意のあるコンテンツを注入し、受信エージェントの動作を操作する。エージェントの自律性は、侵害されたエージェントが人間の介入なしに悪意のあるメッセージを伝播する可能性があるため、この脅威を増幅させる。 | メッセージを受信するエージェント、操作されたエージェントによって制御されるシステム | 高 | 大(潜在的に) | M デジタル署名: すべての A2A メッセージにデジタル署名を実装し、整合性と否認防止を確保する。メッセージが有効と見なされる前に、複数の信頼されたエージェントからの承認を必要とするマルチ署名スキームを実装する。 入力検証: メッセージパーツやメタデータを含むすべてのメッセージコンテンツに厳格な入力検証を実施する。 コンテンツフィルタリング: メッセージ内の悪意のあるコンテンツを検出してブロックするためにコンテンツフィルタリングを使用する。 | |
| プロトコルダウングレード攻撃 | 攻撃者がエージェントに A2A プロトコルのセキュリティの低いバージョンを使用させる。非決定論的なエージェントの相互作用により、予測がより困難な追加の攻撃ベクトルが開かれる可能性がある。 | A2A エージェント、A2A 通信に依存するシステム | 低 | 大(潜在的に) | 安全なプロトコルネゴシエーション: 相互認証を伴うトランスポート層セキュリティ(TLS)などの安全なプロトコルネゴシエーションメカニズムを実装し、エージェントが最も安全なプロトコルバージョンを使用するようにする。 廃止ポリシー: 古いプロトコルバージョンに対する廃止ポリシーを明確に定義し、実施する。 | |
| 信頼できる企業を装った悪意のある A2Aサーバ | 攻撃者が信頼できる企業や組織が運営しているように見せかけた悪意のある A2A サーバをセットアップし、エージェントを騙して通信させ、機密情報を漏洩させたり、悪意のあるタスクを実行させたりする可能性がある。 | エージェント、ユーザー/組織(データ窃取の被害者)、A2A 運用に依存する組織、なりすまされた信頼できる企業(評判の損害) | 中 | 大(潜在的に) | サーバ ID の分散型識別子(DIDs): エージェントと同様に、A2A サーバは DID を使用して識別され、その DID ドキュメントは検証可能で定期的に更新されるべきである。A2A プロトコルは、サーバからエージェントへの通信に DID ベースの認証を義務付けるべきである。 Agent Cards の証明書透明性(CT): SSL/TLS 証明書に似た証明書透明性(CT)のようなメカニズムを実装する。Agent Cards は公開ログ(例:ブロックチェーンや分散型台帳)に登録でき、エージェントが Agent Card が正当であり、改ざんされていないことを検証できるようにする。 相互 TLS(mTLS)認証: エージェントと A2A サーバ間の相互 TLS(mTLS)認証を強制する。 サーバードメインの DNSSEC: A2A サーバの Agent Card にドメイン名を含む URL が含まれている場合、DNSSEC でドメインを保護し、DNS スプーフィング攻撃を防ぐ。 エージェントレジストリ検証: A2A サーバと対話する前に、エージェントは信頼されたエージェントレジストリを参照し、サーバが正当であることを検証すべきである。 Agent Card 署名検証: エージェントはサーバの公開鍵または DID を使用して Agent Card を暗号学的に検証し、カードが改ざんされていないことを確認すべきである。 重要操作に対する多要素認証: 機密性の高い操作の場合、エージェントは A2A サーバと通信する前に多要素認証(MFA)を要求すべきである。 行動分析とレピュテーションシステム: なりすましを示唆する異常なサーバ活動パターンを検出するために行動分析を実装する。 監査とログ: エージェントと A2A サーバ間のすべての通信の詳細な監査ログを維持する。 ハニーポットサーバー: 攻撃者を引きつけ、その技術に関する情報を収集するために、ハニーポット A2A サーバをデプロイする。 | |
| 4 | T4.1: DoS 攻撃 | 攻撃者が A2A サーバにリクエストを殺到させ、エージェントが通信不能になる。エージェントの自律的な性質は、DoS 攻撃がエコシステム全体に急速に連鎖する可能性があることを意味する。 | A2A サーバ、A2A サービスを利用するユーザー/組織、エージェントエコシステム | 中~高 | 大 | 堅牢なインフラストラクチャ: ダウンタイムを最小限に抑えるために、冗長で地理的に分散されたインフラストラクチャを使用する。 DDoS 防御: 堅牢な DDoS 緩和策を実装する。 レート制限: 過剰なリクエストを防ぐためにレート制限を実装する。リアルタイムのネットワーク状況とエージェントの活動パターンに基づいて調整される適応型レート制限を実装する。 |
| 5 | ログデータの隠蔽・改ざん | 攻撃者が悪意のある活動を隠蔽するためにログエントリを変更または削除する。エージェントの動作の複雑で予測不可能な性質は、正当な活動と、操作されたログによって隠蔽された悪意のある行動を区別することをより困難にする。 | セキュリティチーム、監査担当者、インシデントレスポンダー、ログの整合性に依存する組織 | 中 | 大(潜在的に) | 安全なログ記録インフラストラクチャ: 強力なアクセス制御を備えた安全なログ記録インフラストラクチャを使用する。 ログ整合性監視: チェックサムまたはデジタル署名を使用してログデータの整合性を検証する。 異常検出: エージェントの固有の非決定論性を考慮に入れた高度な異常検出技術を採用する。 |
| 6 | エージェントの認証情報への認可されないアクセス | 攻撃者がエージェントの資格情報(例: 秘密鍵)にアクセスし、エージェントになりすまして悪意のある行動を実行できるようにする。エージェントが検証可能な資格情報を動的に取得および提示するため、侵害されたエージェントは迅速に強力な新しい能力を獲得し、損害の可能性を拡大させる。 | エージェント所有組織、侵害されたエージェントがアクセスするシステム | 高 | 大 | 安全な鍵ストレージ: エージェントの資格情報をコードに直接埋め込まない。ハードウェアセキュリティモジュール(HSM)または安全な鍵管理サービスを使用する。 鍵のローテーション: エージェントの資格情報を定期的にローテーションする。 多要素認証: ユーザーが実際に制御していることを確認するために MFA を使用する。 |
| 機微情報へのコンプライアンスの欠如 | エージェントが PII を含むデータを適切な保護なしに送信、受信、処理する。エージェントの自律性がこれらの脅威を強める。 | 機密データを扱う組織(法的・経済的罰則)、個人(PII の所有者) | 中~高 | 大(潜在的に。法的・経済的罰則を伴う) | データ最小化: 個人データの収集を削減する。仮名化/匿名化:。 データ暗号化: エンドツーエンドの暗号化と鍵の保護を確実にする。 | |
| 委任権限の濫用 | 実装の脆弱性により、エージェントが与えられた権限を超える可能性がある。 | 権限を委譲した組織、エージェントが動作するシステム | (明示されていない。なお実装に依存する可能性が高い) | (明示されていないが一般的に委任権限の濫用による影響は大きい) | 明示的なユーザー同意:。 詳細な監査:。 厳格なトークン検証:。 | |
| 7 | 悪意のあるエージェントの相互作用 | 侵害されたエージェントが他のエージェントと相互作用し、危害を与えたり、脆弱性を悪用したり、予期しない結果を引き起こしたりする。エージェントの ID が変化し、動作が予測不可能なため、あるエージェントが他のエージェントよりも大きな損害を引き起こす可能性を予測することは困難である。 | エコシステム内の他のエージェント、エージェントに接続されたシステム | 中~低 | 高(潜在的に影響度が高いと想定される) | 安全なエージェント間通信: エージェント間の相互作用に安全な通信プロトコルと認証メカニズムを使用する。 エージェントレピュテーションシステム: エージェントの動作を追跡し、悪意のあるエージェントを識別するためにレピュテーションシステムを実装する。レピュテーションシステムは、エージェントの ID の動的な性質を処理でき、操作に耐性がある必要がある。 サンドボックス化: 侵害されたエージェントの影響を制限するために、エージェントを相互に隔離する。エージェントが定義された境界を超えるのを防ぐために、ランタイム監視とポリシー実施を実装する。 |
出典:「Threat Modeling Google’s A2A Protocol with the MAESTRO Framework」6: Threat Modeling Results: Applying MAESTRO Layer by Layerより弊社翻訳
※ 本図はOWASPが定義するMAESTROモデルをベースに記載されたhttps://cloudsecurityalliance.org/blog/2025/04/30/threat-modeling-google-s-a2a-protocol-with-the-maestro-frameworkの6: Threat Modeling Results: Applying MAESTRO Layer by Layerを弊社にて翻訳、表に編集しなおしたものです。
AIエージェント時代における標準プロトコルのリスク管理
AIエージェントの普及に伴い、MCPやA2Aといった標準プロトコルは不可欠な基盤となりつつあります。しかし、標準化による利便性の裏側には、同じ脆弱性が広範囲に拡散するリスクが潜んでいます。リスク管理の基本は「標準=安全」と思い込まず、実装ごとにセキュリティ要件を精査することです。特にアクセス制御、暗号化、監査ログといった基礎的な対策をプロトコルレベルで徹底する必要があります。
さらに今後は、従来の「人間を前提としたセキュリティモデル」では対応できない課題が顕在化していくことが予想されます。次回第5回では、Non Human Identity(NHI)の登場や制御不能なAIエージェントといった新たな脅威に焦点を当て、従来型セキュリティの限界とその打開策について考察します。
―第5回「AIとセキュリティ:Non‑Human Identity とAIエージェントの課題」へ続く―
【連載一覧】
第1回「Vibeコーディングとプロンプトエンジニアリングの基礎」
第2回「プロンプト以外で効率化!開発体験の改善手法」
第3回「AIエージェント時代のコーディング:MCPとA2Aとは」
第4回「MCPの脆弱性とA2A脅威分析から学ぶセキュリティ実装」
第5回「AIとセキュリティ:Non‑Human Identity とAIエージェントの課題」
第6回「AIエージェントのセキュリティ対策と今後の展望」
Security NEWS TOPに戻る
バックナンバー TOPに戻る
ウェビナー開催のお知らせ
「止まらないサイバー被害、その“対応の遅れ”はなぜ起こる?~サイバー防衛の未来を拓く次世代XDR:大規模組織のセキュリティ運用を最適化する戦略的アプローチ~」
「フィッシング攻撃の最新脅威と被害事例〜企業を守る多層防御策〜」
「サイバーリスクから企業を守る ─脆弱性診断サービスの比較ポイントとサイバー保険の活用法─」
最新情報はこちら