Security NEWS TOPに戻る 戻る
脆弱性とは、システムやソフトウェア、ネットワークなどに存在する「セキュリティ上の弱点」を指します。この弱点を攻撃者に悪用されると、不正アクセスや情報漏えいなどのサイバー攻撃につながる可能性があります。この言葉の意味を正しく理解することは、サイバーセキュリティを理解するうえで非常に重要であり、企業や組織が安全にシステムを運用するためには、脆弱性を早期に発見し、適切に対策することが重要です。本記事では、脆弱性の正しい意味、サイバー攻撃との関わり、企業が取るべき対策までを体系的に整理し、分かりやすく解説します。
脆弱性とは何か?
「脆弱性(ぜいじゃくせい)」とは、システムやソフトウェア、ネットワークなどに存在する「セキュリティ上の弱点」や「欠陥」のことです。この弱点が存在すると、攻撃者に悪用されることで、不正アクセス、情報漏洩、マルウェア感染、サービス停止といったサイバー攻撃の被害につながる可能性があります。
脆弱性の多くは、「プログラムの設計ミスやコーディングミスなどによるバグ」になります。バグが存在せず正しく動作するプログラムやWebアプリケーションであっても、設計者が想定しないやり方で機能が悪用され、 結果としてサイバー攻撃が成立する場合には、その「悪用されうる機能設計」が脆弱性とみなされます。
企業では、こうした脆弱性を早期に発見するために「脆弱性診断」を実施することが重要です。→「脆弱性診断の必要性とは?ツールなど調査手法と進め方
しかし、いざ「脆弱性 意味」「脆弱性とは何か?」と問われると、具体的に説明できない人も少なくありません。
脆弱性の読み方と語源
「脆弱性」は「ぜいじゃくせい」 と読みます。
「脆」(ぜい):もろい、こわれやすいという意味
つまり、「壊れやすく弱い性質」という意味で、ITセキュリティ分野では“攻撃に利用される欠陥や弱点”を指す言葉として使われます。また英語ではvulnerability(バルネラビリティ=「攻撃を受けやすいこと」の意)と呼ばれます。
脆弱性の代表例
脆弱性はさまざまな原因によって発生します。ここでは代表的な脆弱性の例を紹介します。
ソフトウェアの脆弱性
ソフトウェアのプログラムに不具合があると、それが脆弱性となる場合があります。例として、
入力値の検証不足
バッファオーバーフロー
SQLインジェクション
などが挙げられます。このような不具合を攻撃者が悪用すると、データベースの情報が盗まれたり、システムが乗っ取られたりする可能性があります。
これらの代表的なWebアプリケーションのセキュリティリスクは、OWASP Top10として国際的な指標としてまとめられています。OWASP Top10 2025:2021版からの変更点と企業が取るべきセキュリティ強化ポイント
設定ミスによる脆弱性
システムの設定が適切でない場合も脆弱性の原因になります。代表的な例として
管理画面がインターネットに公開されている
デフォルトパスワードのまま運用している
不要なポートが開放されている
などが挙げられます。こうした設定ミスは攻撃者にとって侵入の入り口となることがあります。
設計上の問題による脆弱性
システムの設計段階に問題がある場合、構造的な脆弱性が発生することがあります。
例えば
認証機能の設計ミス
権限管理の不備
セッション管理の問題
などです。設計段階の脆弱性は、後から修正するのが難しい場合も多く、開発段階からのセキュリティ対策が重要になります。
脆弱性が攻撃の入口になる理由
攻撃者はまず「侵入できる弱点がないか」を探します。この弱点こそが脆弱性です。例えば、
公開された脆弱性のパッチを適用していない
古いプログラムを長期間放置している
不要なサービスやポートを開けたまま
といった状態は、攻撃者に「ここから入れる」と示しているようなものです。実際、多くのサイバー攻撃は “脆弱性の悪用” から始まっています。
ここまでの説明でお気づきかもしれませんが、「脆弱性が多く報告されている」ことは必ずしも「品質が悪い」ことを意味するのではありません。
脆弱性が悪用されるとどうなる?
脆弱性が攻撃者に悪用されると、企業や組織に大きな被害をもたらす可能性があります。代表的な被害をご紹介します。
重要情報(顧客情報・社員情報・機密情報等)の漏洩
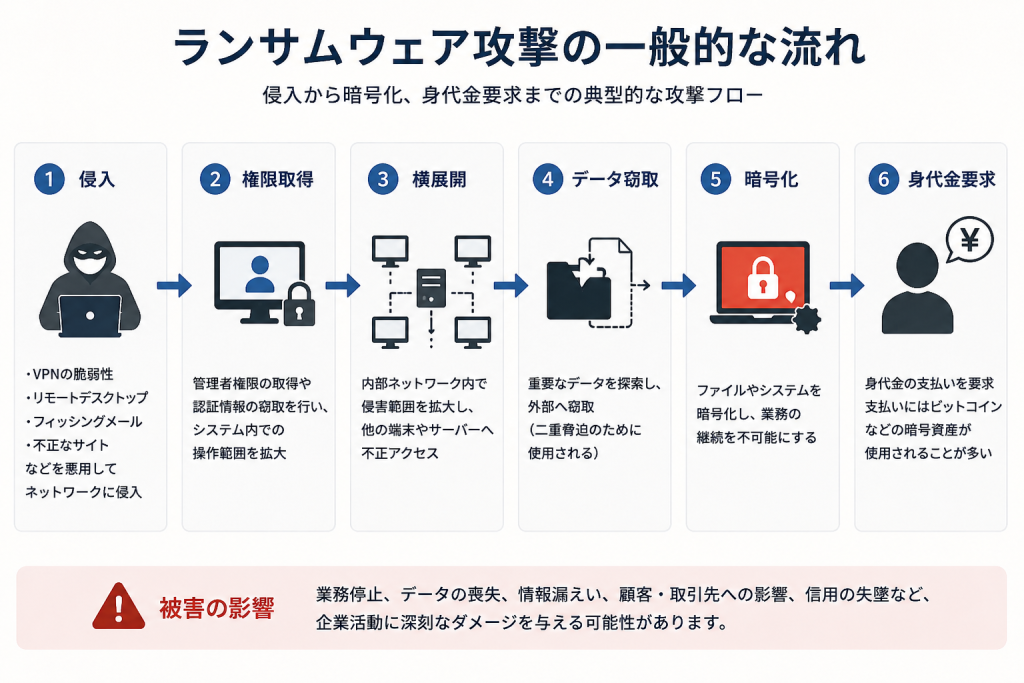
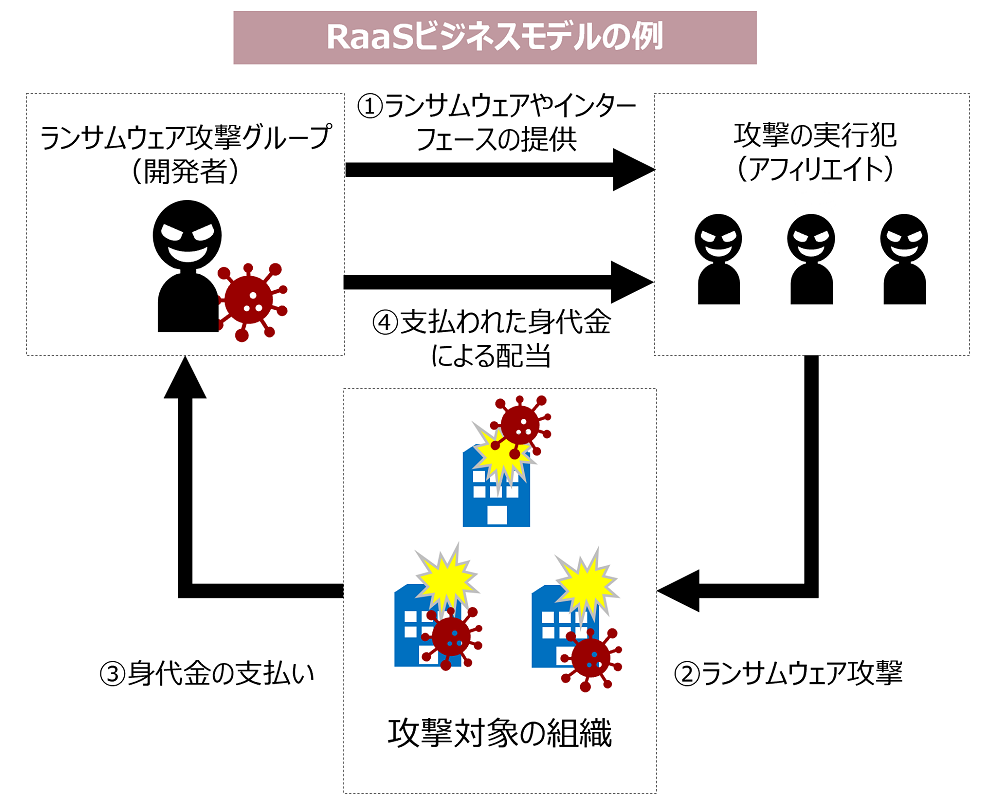
サイバー攻撃(ランサムウェア攻撃等)を受けるリスク
サービス停止や業務停止リスク
特に近年は、脆弱性を狙った攻撃が高度化し、攻撃者が自動的に弱点を探索するツールも普及しています。「気づいたら侵入されていた」というケースも少なくありません。
脆弱性を悪用したセキュリティ事故は日々発生しています。SQAT.jpでは以下の記事でも取り上げていますので、ぜひあわせてご参考ください。
● 「定期的な脆弱性診断でシステムを守ろう!-放置された脆弱性のリスクと対処方法- 備えあれば憂いなし!サイバー保険の利活用
脆弱性を防ぐための対策
脆弱性を放置すると、重大なセキュリティ事故につながる可能性があります。脆弱性対策の基本的な考え方としては、システムの欠陥をつぶし、脆弱性を無くすこと(「攻撃の的」を無くすこと)が最も重要です。企業での実践方法としては以下の項目があげられます。
修正パッチの適用
ソフトウェアやOSの定期的なアップデート アップデートされた最新バージョンでは既知の脆弱性や不具合が修正されていますので、後回しにせずに更新を行うようにしてください。
セキュアプログラミングで脆弱性を作りこまない体制に 自組織で開発したソフトウェアやWebアプリケーション等の場合は、サービスが稼働する前の上流工程(開発段階)から、そもそも脆弱性を作り込まない体制を構築することが大切です。
また、テレワーク環境では、以上の項目に加え、クライアントサイドでのパッチ適用が適切に行われているかをチェックする体制を構築することも重要です。また、シャドーITの状況把握も厳格に実施する必要があります。
「IT部門が知らないサービスを勝手に利用され、結果として脆弱性の有無について未検証のクライアントソフトやブラウザプラグインが使われていた」という事態は防がねばなりません。
脆弱性情報はWebサイトでチェックできる
脆弱性は、さまざまなソフトウェアやプラットフォームで日々発見されています。そうした情報は、多くの場合、ソフトウェアやプラットフォーム提供元のWebサイトに掲載されます。定期的にチェック するとよいでしょう。
JVNを利用した脆弱性情報の正確な情報収集と活用法
一般社団法人JPCERTコーディネーションセンターとIPA(独立行政法人情報処理推進機構)では、公表された脆弱性情報を収集して公開するサービス「JVN(Japan Vulnerability Notes)
脆弱性情報ソースと活用
インシデントやゼロデイの発生情報については、セキュリティ専門のニュースサイト、セキュリティエバンジェリストのSNSなどからも情報をキャッチできます。
情報の裏取りとして、セキュリティベンダからの発表やtechブログ等を参照することもと重要となります。攻撃の影響範囲や危険度を確認するには、Exploitの有無を技術者のPoC検証ブログやNVD等で確認することも有効です。
ツールを使って脆弱性を見つける
脆弱性を発見するためのソフトウェアは「チェックツール」「スキャンツール」「スキャナ」
有償ツール 無償ツール Webアプリケーション向け AppScan、Burp Suite、WebInspect など OWASP ZAP など サーバ、ネットワーク向け Nessus(一部無償)、nmap など Nirvana改弐、Vuls など
「脆弱性診断」サービスで自組織のソフトウェアの脆弱性を見つける
上記でご紹介したツールを使えば、脆弱性のチェックを自組織で行うことが可能です。しかし、前述の通り、「脆弱性が存在するのに報告されていない」ために情報がツールに実装されていないソフトウェアも数多くあります。また、一般に広く利用されているソフトウェアであれば次々に脆弱性が発見、公開されますが、自組織で開発したWebアプリケーションの場合は、外部に頼れる脆弱性ソースはありません。さらに、実施にあたっては相応の技術的知識が求められます。そこで検討したいのが脆弱性診断サービスの利用です。脆弱性の有無を確認するには、脆弱性診断が最も有効な手段です。
脆弱性診断サービスでは、システムを構成する多様なソフトウェアやWebアプリケーション、API、スマホアプリケーション、ネットワークなどに関し、広範な知識を持つ担当者が、セキュリティ上のベストプラクティス、システム独自の要件などを総合的に分析し、対象システムの脆弱性を評価します。組織からの依頼に応じて、「自組織で気付けていない脆弱性がないかどうか」 「脆弱性に対して施した対策が充分に機能しているか」
対策が正常に機能しているかの検証を含めた確認には専門家の目線をいれることをおすすめしています。予防的にコントロールをするといった観点も含め、よりシステムを堅牢かしていくために脆弱性診断をご検討ください。脆弱性を防ぐためには、ソフトウェア更新や設定の見直しだけでなく、定期的なセキュリティ診断を行うことが重要です。
特に企業のシステムでは、脆弱性診断に加えて、実際の攻撃を想定したペネトレーションテストを実施することで、セキュリティ対策の有効性を確認することができます。ペネトレーションテスト(侵入テスト)とは?
脆弱性との共存(?)を図るケースもある
最後に、診断で発見された脆弱性にパッチをあてることができないときの対処法をご紹介しましょう。
まず、「パッチを適用することで、現在稼働している重要なアプリケーションに不具合が起こることが事前検証の結果判明した」場合です。このようなケースでは、システムの安定稼働を優先し、あえてパッチをあてずに、その脆弱性への攻撃をブロックするセキュリティ機器を導入することで攻撃を防ぎます。セキュリティ機器によって「仮想的なパッチをあてる」という対策になるため、「バーチャルパッチ」
また、脆弱性が発見されたのがミッションクリティカルなシステムではなく、ほとんど使われていない業務アプリであった場合は、脆弱性を修正するのではなく、そのアプリ自体の使用を停止する
なお、前項でご紹介した脆弱性診断サービスの利用は、脆弱性に対して以上のような回避策をとる場合にも、メリットがあるといえます。発見された脆弱性について、深刻度、悪用される危険性、システム全体への影響度といった、専門サービスならではのより詳細な分析結果にもとづいて、対処の意思決定を行えるためです。
脆弱性に関するよくある質問
▼脆弱性とは簡単にいうと何ですか?
▼脆弱性とバグの違いは何ですか?
▼脆弱性と脅威の違いは?
まとめ
「脆弱性とは何か?」を正しく理解することは、サイバー攻撃に備えるうえで最も基本かつ重要なステップです。脆弱性は放置すれば攻撃者にとって“格好の入口”となり、情報漏えいやサービス停止など重大な被害を招きかねません。自社システムの安全性を確保するためにも、日頃から更新・診断・運用の見直しを行い、脆弱性を適切に管理することが求められます。
関連情報
● 脆弱性診断の必要性とは?ツールなど調査手法と進め方
VIDEO
公開日:2020年7月20日
編集責任:木下
Security NEWS TOPに戻る 戻る
年二回発行されるセキュリティトレンドの詳細レポート。BBSecで行われた診断の統計データも掲載。
サービスに関する疑問や質問はこちらからお気軽にお問合せください。